After reading some fantastic suggestions for the CMIP6 Hackathon I started to see a common theme emerge for some of the suggestions. At least four of the proposals are focused on interpolation and regridding of model output:
- Sample model like observations
- Pipelines for downscaling CMIP6 data
- XGCM: Your friend and helper for naughty grids
- Plotting ocean variables in density coordinates (using xhistogram)
These are all important topics that address common problems in using and analyzing ocean models (and other earth system models as well). The hackathon proposals should be targeted, with achievable goals. I thought it would be good to start a more general discussion about longer term goals, problems, and best practices in regridding and interpolation.
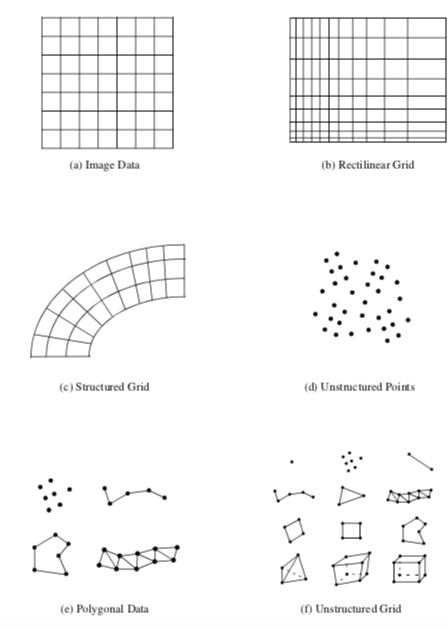
There are three categories of interpolation:
- unstructured data mapped to a structured grid
- data on a structured grid mapped to unstructured points
- data on a structured grid mapped to another structured grid (i.e., regridding)
The four CMIP6 Hackathon proposals are focused on the second and third points. As I see it, these two categories define the two most common use cases for model analysis. The first is used either in creating data-only climatologies (e.g., Levitus) – a career, not an afternoon – or dynamically ‘interpolated’ using a model with some sort of data assimilation. So, if we are interested in model analysis using Pangeo tools, we should focus on the second two.
Interpolation
Interpolating gridded data to random points is straightforward in theory. A common approach is to use Delaunay interpolation, which does not exploit the fact that the original data is on a structured grid. Other algorithms, like quad interpolation (coded up in gridded) can use the information inherent in the grid structure.
A good, general trial case is a glider or profiling float that traces a four-dimensional path through the model field. In my own experience, this is always a frustratingly slow process. It seems the only way to speed this up is to subset the data in a clever way so that interpolation is done only over the data that are needed for a particular timestep.
Re-gridding
There are conservative solutions to the 2D problem, like SCRIP and ESMF. SCRIP, for example, returns a sparse regridding matrix that can be reused, but as far as I know has not been wrapped in a python package. ESMF at least has been translated to an xarray friendly package, xESMF. I’m not sure if the regridding using histograms is conservative, but this might be the most efficient way to translate to a grid that changes in time (e.g., z -> density coordinates).
Though ESMF supports 3D regridding, in practice I have often seen people vertically (1D) interpolate to a z-grid (if not already), then do 2D regridding on each z-level, and finally vertically (1D) interpolate to the desired vertical grid in the target coordinates.
Questions for discussion
- What do people do now?
- What are the best practices?
- What are good-enough practices?
- What’s missing?



{kind=link}