Hello!
I am researching best practices to load spatial, geoscience data (generally netCDF/Grib via xarray) to various ML packages. Two things kept coming up:
-
xbatcher project: GitHub - pangeo-data/xbatcher: Batch generation from xarray datasets
-
Noah Brenowitz blog post on netCDF to Tensorflow. I copied Noah’s work here, but my graph is not quite the same netCDF2ML/noah_demo.ipynb at main · ThomasMGeo/netCDF2ML · GitHub .
Main questions are:
-
Are there other blogs, how-to’s, general documentation I should be aware of?
-
For researchers with 10-100’s of GB’s in netCDF’s per project, are their rules of thumb or ‘bad ideas’ that I should avoid?
3 Likes
Hi @ThomasMGeo, the answer on ‘how’ to read 10-100s of GBs of NetCDF files partly depends on whether you want to go for A) pure speed, or B) readability/metadata preservation.
If speed is the main goal, then you’ll probably want to convert those NetCDFs into a more tensor-friendly format like tfrecords, .npy files, webdataset, or so on. Zarr might be speedy as well if you can optimize the chunk sizes (which is another topic in itself).
If you like metadata and are looking at keeping things more in the xarray world (at least until the last minute when you throw things into the GPU), then xbatcher is definitely recommended for doing multi-dimensional name-based slicing or fancy indexing. Cc @maxrjones and @jhamman. See also Efficiently slicing random windows for reduced xarray dataset - #25 by rabernat for another xarray-orientated example.
Personally, I’m more in the Pytorch ecosystem, and torchdata (see Tutorial — TorchData 0.4.1 (beta) documentation) with its composable Iterable-style DataPipes is the fancy new way for creating ML data pipelines. As a shameless plug, I’ve got an example tutorial at Chipping and batching data — zen3geo that walks through using DataPipes to load multiple GeoTIFFs with rioxarray, chipping into 512x512 tiles with xbatcher, and loading into a Pytorch DataLoader. Not exactly NetCDF, but the general workflow post rioxarray.open should be reusable.
Yes, avoid reinventing the wheel if possible  Asking on this forum definitely puts you on the right track. At the end of the day, you’ll definitely need to customize things for your particular dataset, but there are some core/fundamental tools that should hopefully be fairly standard for people doing things the Pangeo/xarray way.
Asking on this forum definitely puts you on the right track. At the end of the day, you’ll definitely need to customize things for your particular dataset, but there are some core/fundamental tools that should hopefully be fairly standard for people doing things the Pangeo/xarray way.
5 Likes
Really appreciate all the links/thoughts! Yes, main goal is to not reinvent the wheel for many reasons  Thank you for putting this all together.
Thank you for putting this all together.
Today, I am more on the metadata/more in the xarray realm than pure speed, but good to know of whats out there if a project objectives/size changes that.
Best,
Thomas
That’s basically my experience - the more efficiency, speed etc. you want, the rawer the data you want - so big projects, the arrays etc. will be faster.
We were actually toying with going even closer to metal raw binary data for a recent 200TB project. That would have meant rewriting some things - so there’s a speed tradeoff there too.
Are you looking at doing it a lot, repeatably, or a one-off?
1 Like
While this is the conventional wisdom, in the blog post below, @nbren12 showed that, in fact, netCDF can be just as fast as those other formats in ML training loops.
3 Likes
I love how this discussion is steering more from metadata to speed  Just to clarify, NetCDF can indeed be fast enough if you’re going from File → CPU-RAM → GPU-RAM (assuming you’ve got enough I/O, RAM, etc) as @rabernat pointed out.
Just to clarify, NetCDF can indeed be fast enough if you’re going from File → CPU-RAM → GPU-RAM (assuming you’ve got enough I/O, RAM, etc) as @rabernat pointed out.
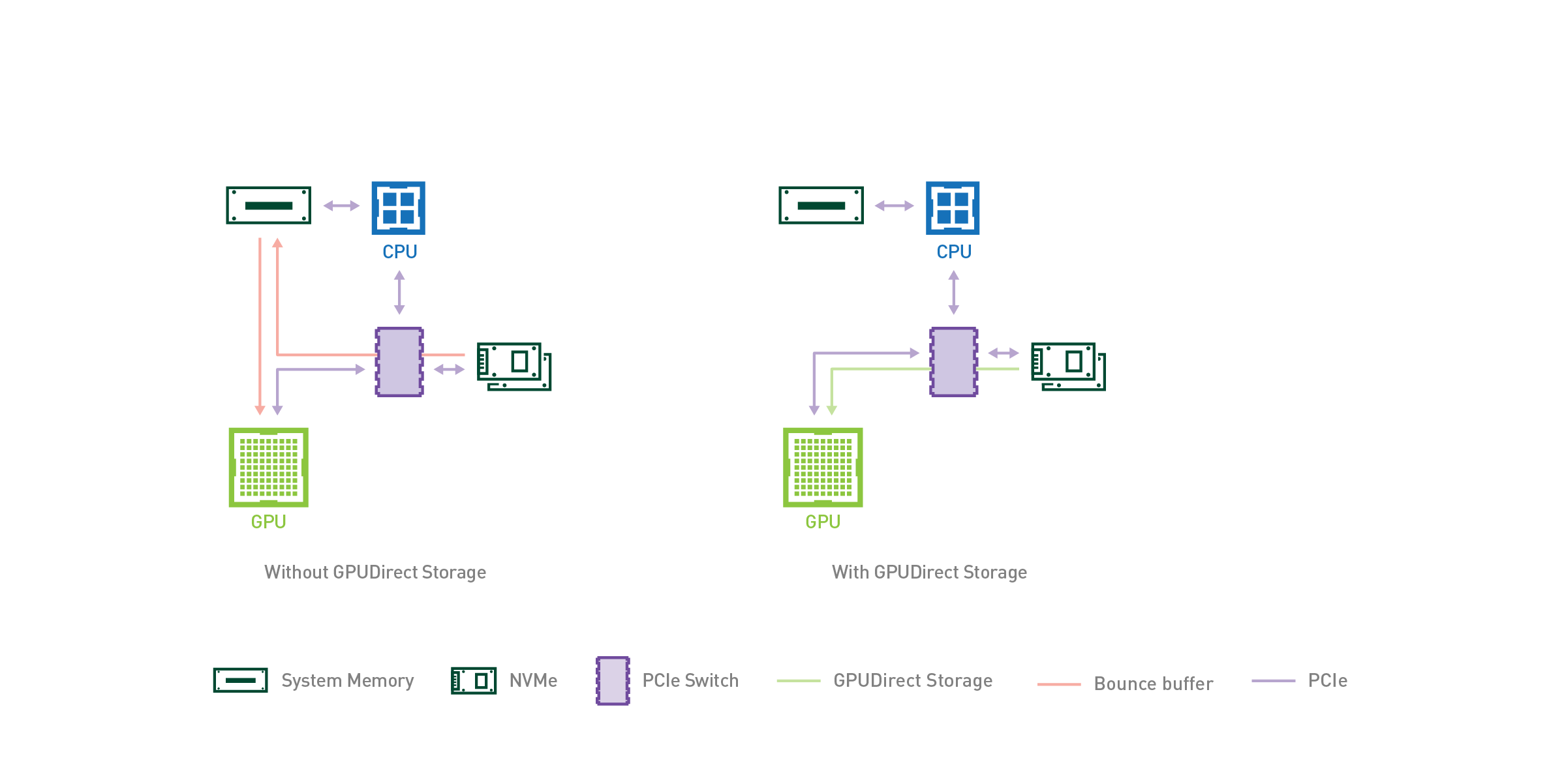
Now, if you want end-to-end pure speed (and have enough GPU RAM) then the CPU-RAM to GPU-RAM data transfer will be the main bottleneck. You’ll then need to look at things like GPU direct storage:

This would involve using libraries that handle loading/pre-processing directly on the GPU like:
Caveat with this is that you can’t read NetCDFs or most ‘geo’ formats directly into GPU yet (as far as I’m aware). Relevant issues include:
That said, there is a way to map CPU/NumPy tensors to GPU/CuPy tensors in xarray as with cupy-xarray, and then use GPU zero-copy methods to convert CuPy tensors to Pytorch/Tensorflow tensors. See:
But again, you will still need to load the NetCDF from File → CPU-RAM → GPU-RAM until someone figures out a more direct NetCDF file → GPU-RAM path. This has been on my wishlist for quite a while, and most of the interoperability standards are in place, we just need to get some smart people to do it 
2 Likes
Oo, shiny! Yes I’ve got a GPU, let me test that out 
Edit: I’ve documented the installation/setup commands to try out @dcherian’s xr.open_dataset(store, engine="kvikio") proof of concept here if anyone is interested. Very hacky stuff but it works!
Edit 2: New blog post out on going from Zarr stores to GPU-backed xarray objects! Read it at Enabling GPU-native analytics with Xarray and kvikIO 
4 Likes