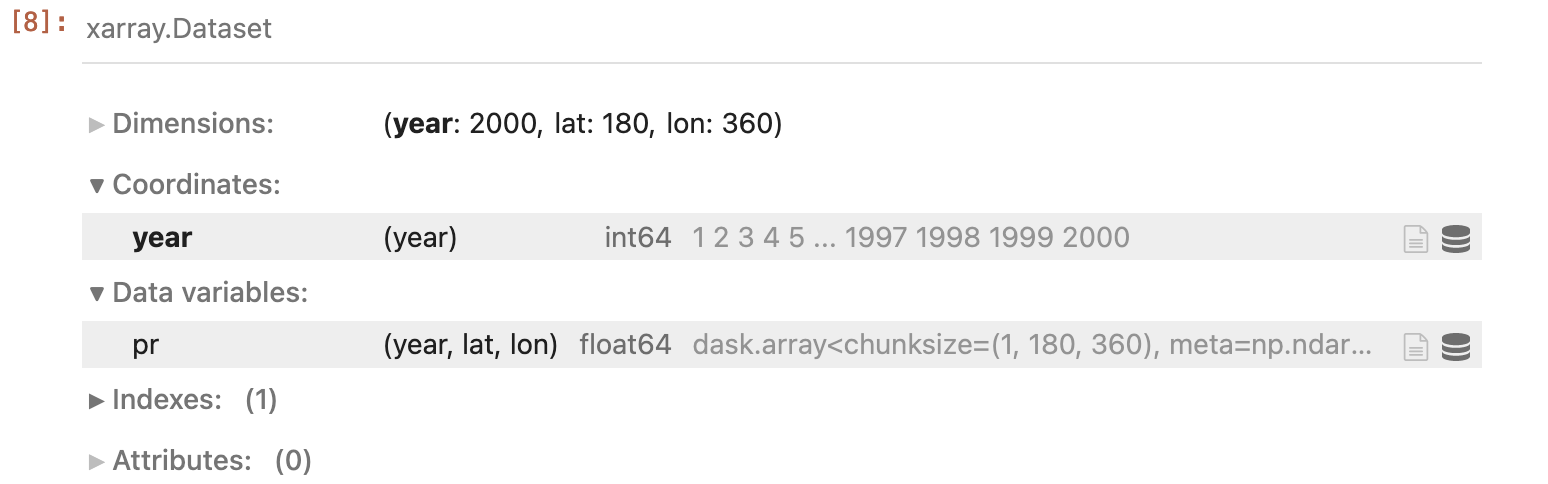
I am working with piControl data from CMIP6 and handling 2000 years of daily data. While performing some analysis, I encountered memory error and am unable to write the result to a NetCDF file. The error message I received is as follows:
“MemoryError: Unable to allocate 176. GiB for an array with shape (730485, 180, 360) and data type float32”
To clarify, after the final calculation, there is only one value per year. Therefore, the final output shape would be (2000, 180, 360).
Any assistance or suggestions to resolve this issue would be greatly appreciated.
I suspect that’s because at some point during your calculations you accidentally load the entire data into memory.
To verify, try computing a single variable of the output shape (something like result["variable"].compute()). If this succeeds, you know that something goes wrong when writing to disk. However, if it fails (as I suspect), then that means that the issue is with the way you implemented your computation.
Either way, it would be great if you could post a (trimmed down) version of the code, as otherwise all we can do is guess.
The calculation completes in 30 seconds until the yearly_r95ptot variable is calculated. The memory error occurs when I try to write the variable to a NetCDF file.
Right now it seems like you generate very large arrays due to broadcasting in the group > pn call?
I recommend inspecting each group manually, and I bet that group.where(group > pn) has the shape of the original array. In that case you would be trying to load size(wet_days) * n_years into memory.
@chaithra could you provide the particular model, grid, and other facets from the CMIP output your are working with? This would help us to look for the same data in the cloud and test this.
Perhaps you could just print the datasets attributes from your file datasets object here?
This is the key observation. Since you’re operating on a year of data at a time, you don’t need to rechunk to time=-1 instead you can rechunk so that a year of data is in a single chunk. This rechunking is required for computing the quantile.
# rechunk to yearly frequency
from xarray.groupers import TimeResampler
ds = ds.chunk({"time": TimeResampler(freq="AS")})
ds
I think it’s worth asking–what could we do at the API level to make things “just work” more automatically? What @chaithra wants to do is pretty standard. Yet the tricks required to make it succeed are obscure and only obvious to experts.
I would like to get your suggestions on improving the performance of my calculations.
To my understanding, your code uses yearly 95th percentile values as a threshold. I want to compute the climatological 95p values instead of the yearly values. Please see the attached snapshot. Unfortunately, the process is significantly slower than expected.
Your screenshot with chunksize=(182621,180, 360) is concerning. That’s only 4 chunks in the whole array, which limits the amount of parallelism you can use (with dask at least). Where is this chunksize coming from? How many days or months or years data are stored in a single netCDF file?
when does setting chunks get materialized? It confuses me that this gets set at read time or as a property of an object (I can’t find out how to do this properly for a multi-file input that I want different chunk sizes for in a Zarr I create). I expect it to be a property at write time, and that doesn’t seem to be the case. Is this described somewhere in examples? (I’m struggling with the documentation about what’s the right thing to do. Thanks!).