Much of NASA Earthdata especially those from PO.PAAC are now hosted on S3. Using parallel computing is the key to unlock the potential of hosting the data in the cloud. I could not find much information here, but has anybody used Dask (or MPI) using an AWS cluster directly on NASA Earthdata which requires a (free) Earthdata login (EDL)? How was your experience?
Hi, yes, that example is now a bit dated and doesn’t go into dask. You might also have a look at materials from the more recent ICESat-2 hackweek: Cloud Computing Tutorial — ICESat-2 Hackweek 2022
Not sure what dataset you’re interested in. Working with dask on a single machine is straightforward because you can read credentials from a local file (~/.netrc), but on a distributed cluster you need some way of moving credentials (ideally temporary ones) across machines. Here is another example for raster data using data from LPDAAC CloudDAAC_Binders/s3_v_http.ipynb at main · rmg55/CloudDAAC_Binders · GitHub
I took a look at the tutorial. It is very useful for laying out the process. But it seemed to be more complicated than necessary. Is this the reason why not many existing tutorials use earthdata to demo large-scale computation? What is your experience @rabernat?
@scottyhq I am interested in using cluster with earthdata in general. MUR SST at 1km is one example for its size.
I don’t have any insights on Earthdata login that Scott and Tom do not. We have usually been able to make it work using fsspec to pass through the credentials
It would be great if someone would write a definitive guide on how to use Earthdata data with Pangeo. Why not just as a forum post here on Discourse?
To be honest, this is an issue to raise with NASA, not Pangeo. NASA has created a pretty complicated wall around their data with Earthdata login. We are doing our best to deal with it given those constraints.
A belated reply that this is on my and @betolink’s long to-do list, because it’s a pain point for icepyx as well (I know Luis’ earthdata library handles S3 authentication, but not sure if its set up for parallel computing). I’m anticipating that I can dig in on this sometime this summer (we have a very crude start here).
@JessicaS11 and @betolink , I’ve also had this on my todo list – I’d be happy to team up this summer if you want to organized a mini-hackathon of sorts.
@JessicaS11@jhkennedy I’d also be interested in assisting with developing a guide for this if we have plans for tackling this later this summer. As a side note, there are several ongoing internal NASA efforts to improve the access mechanics of authentication for DAAC managed object storage. Some of the considerations are covered in this recent presentation Token Expiration Whitepaper - Google Docs
@sharkinsspatial I’m at ASF DAAC and work on HyP3 so know a bit about those efforts, and I can definitely say I personally endorse that whitepaper’s conclusions. I’d be happy to know if there’s any support I can lend to it.
We here at JPL/PODAAC have been exploring this. So far we have made progress using AWS lambda to parallel process granule-based calculation, but no luck on Dask. I knew several other groups are exploring this too. It will be a fun summer project.
I made a baby step on this topic. Here is a notebook. The next target is using Dask to lazy-load POCLOUD MEaSUREs-SSH level-4 gridded product and perform distributed calculation.
Same here, this has been on my list for quiet some time now. One of the things to distinguish here is the use of a local cluster vs distributed cluster. For a local cluster case, I think what Scott did should work out of the box, for a distributed cluster… things could get a bit tricky with the S3 keys to the worker nodes and the fact that they expire after 1 hour etc. It would be cool if NASA could host a hack week focused only on access patterns to EDL-protected data both direct S3 access and on-prem from the DAACs. As Ryan mentioned, this is more of a NASA problem than a Pangeo issue. Nonetheless, It would be awesome to have some notebooks and/or a blog post on how to actually scale NASA dataset processing with Dask. I’m happy to team up with all of you on this.
We have usually been able to make it work using fsspec to pass through the credentials
@rabernatfsspec does seem to have all the stuff needed. I’ve been kicking around making an edlfs package al la s3fs with @betolink. Idea would be to handle dealing with the credentials for uses (over HTTPS as that’ll should work with all DAAC systems). Does that seem like a reasonable idea? Also makes me wonder if we could get that work funded some how…
Really, EDL has prompted a ton of engineering work to fundamentally solve a NASA policy problem, so I’m hoping internal pushes to change NASA policy would make that package obsolete… but I have no over/under on how likely a policy change would be (well above my pay grade).
@jhkennedy Apologies I had lost track of this thread but just stumbled on edlfs repo that you and @betolink were working on randomly while searching for something else in Openscapes :]. I’m out on vacation this week at the moment and travelling at the beginning of September. What do folks think about trying to organize a sprint around this in mid September?
If you’d like to pursue the fs implementation approach, we’d likely need to find some contributors with deep aibotocore experience. I’m a bit out of my depth determining how to implement timer based token refresh when working with the context manager pattern, but I’m sure there are folks lurking here who would have good recommendations around this.
I like the mid September idea. After some initial prototyping I don’t know if a full-flagged fsspec backend implementation is required to circumvent the EDL issue but it could be an opportunity for improvements.
Joe suggested another workflow(involving TEA) that might just work to avoid the per-DAAC credentials and agree that if this goes forward as a package we’ll need aiobotocore/aiohttp expertise.
I like the mid September idea. After some initial prototyping I don’t know if a full-flagged fsspec backend implementation is required to circumvent the EDL issue but it could be an opportunity for improvements.
@martindurant, maybe you can help advise on whether a new file system is the right path here?
There has been some talk at s3fs about making credentials which can renew themselves after becoming invalid. But I don’t know anything about the specifics of EDL (sorry, haven’t read the thread in detail yet).
Until then, I imagine, for something that is s3-except-auth, you might be best of subclassing S3FileSystem, which already has almost everything you need. That should be much easier than writing a new backend from scratch, although that’s not too hard either.
What do folks think about trying to organize a sprint around this in mid September?
I think that’s a great idea! There’s at least 3 of us at ASF that’d be interested in participating, including @forrestfwilliams .
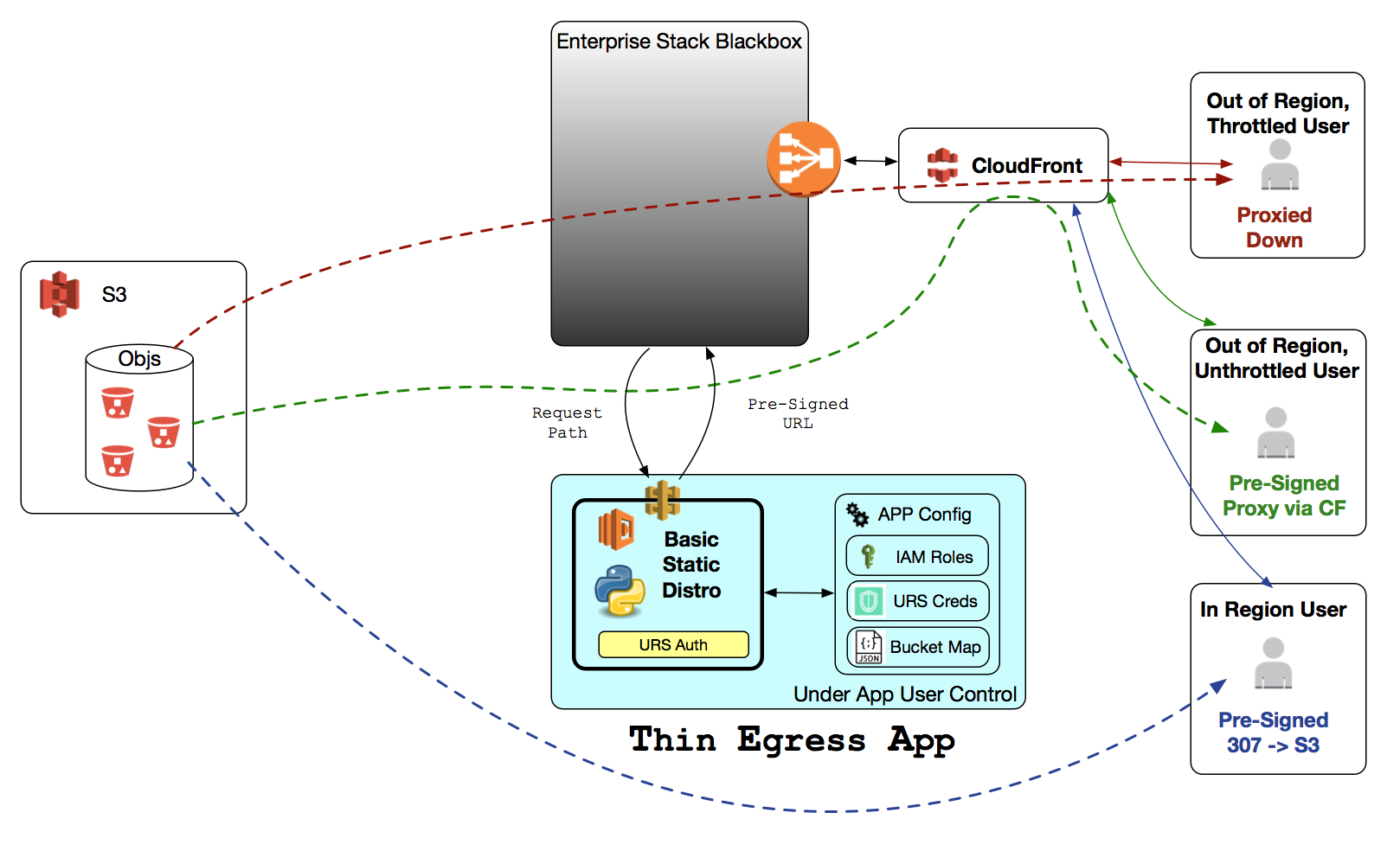
There’s two access patterns for NASA DAACs in this space:
Using EDL and HTTPS only. Stuff is effectively distributed via a DAAC URL that’s redirected to:
a. A CloudFront URL or an S3 signed HTTPS URL if you’re in-region for cloud-hosted data
b. An on-prem URL
By hitting a DAAC specific endpoint, you can get temporary AWS access keys that give you read-only access
I think targeting 1 might make the most sense initially as that’ll mostly just be aiohttp based. Getting 2 working will definitely need self-renewing credentials; maybe it’d make sense to focus some dev. time on adding that to s3fs before adding in the EDL complications? Though a general s3fs solution might be much bigger.
{kind=link}